

The Tale of Ryzen and Firestrike: Problems Ahead?
A few weeks back I spent a bunch of time benching my Ryzen setup. After many hours of benchmarking and documenting results, I found a handful of useful tweaks and general improvements that can be made however, there was one glaring issue that still doesn't make sense. The huge performance discrepancy when running specific core parking settings within the Windows 10 power plan settings in the Firestrike combined test.
image
I first noticed the issue when I was running batches of 3DMark runs to check ram frequency scaling. My scores would randomly drop by approximately 20% for no reason; I hadn't changed a single bios or windows setting for anything. I then ran a batch of tests to see how often this issue would occur, and found that approximately every 1.5 out of 5 runs my combined score would drop at the same settings (I ran a total of 20 tests at the same settings).
To keep this brief, this issue lead me down two paths. The first being the W10 power plan core parking setting and the second investigating whether or not core/CCX configuration had anything to do with the problem. For part one I exclusively used AMD's new Ryzen Power Plan, and simply adjusted the core parking values for testing purposes.
Test Setup:
- R7 1700 @ Stock
- Gigabyte AX370 Gaming 5 (F5G Bios)
- 2x8GB G.Skill DDR 3200 @ 3200 14-14-14-34 1T 1.35v
- EVGA GTX 1070 FTW2 @ Stock (381.65 WHQL)
- EVGA 750w Supernova G2
- Windows 10 Home 64-bit (Creators Update)
Part One
First we will look at how the Windows 10 core park settings affect the Firestrike Combined Score with the AMD Ryzen Power Plan. Below the Combined test was run three times with the stock R7 1700 at 0% (all cores parked) and at 100% (all cores unparked) via the W10 core parking option.

Here we can clearly observe one of the issues at hand. When W10 has all cores unparked (100% setting in power options), the Combined test performs signifcantly worse than with all cores parked. This behavior is only observed with both CCX enabled and 16 threads active, or the R7 1700 being at its' stock configuration and clock speeds. Performance drops on average by 22.5%, with an extreme delta of a 31% loss in performance. Is this due to threads being spread across the CCX? Let's find out.
Next I ran the same test but with the R7 1700 set to 2+2 and 4+0 two observe if latency due to threads being spread across the CCX was detrimental to performance. This was done using the downcore configuration options within the bios.




The results were VERY interesting to say the least. Not only had the behavior due to core parking been reversed, and performing like one would expect, there was almost no performance penalty due to cross CCX communication. With all the cores unparked the performance difference between the 2+2 and 4+0 configuration was 0.4%. The difference with all cores parked was 1%. Both of these values are what I consider to be within margin of error; CCX communication seems to incur no performance penalty.
It was starting to seem like the issue was directly related to how Firestrike itself was dealing with assigning threads and loads properly. This hypothesis seems to ring true when we take a look at performance across threads for each configuration. Thread assignment and loading was observed using the W10 task manager performance monitor.
Below we look at the difference in thread assignment and activity between all cores parked and unparked with the stock 1700.

With all cores parked, thread assignment is sequential from CPU0 to CPU15 with activity falling at CPU9 onward.

With all cores unparked, thread assignment is sporadic with the load spread unevenly across the 16 threads. Having all cores unparked also resulted in a consistently worse combined score, and with this uneven load/thread assignment it makes perfect sense.




Moving on to the 2+2 and 4+0, thread assignment and loading seems to be identical for each configuration. The major difference here being that again we see with all cores parked, thread assignment/load is sequential. When the cores were unparked, thread assignment was more sporadic, but loading was consistent between the 2+2 and 4+0 configuration. This is slightly different from the extremly sporadic loading and thread assignment we saw with the CPU configured for 4+4 with all cores unparked. Unfortunately there is no 8+0 Ryzen cpu to compare.
Now what does all of this mean? The most accurate conclusion I can make from this is that there are clearly some threading issues with the Firestrike combined test. Why Firestrike and not Windows you say? The proof is in the difference in thread loading with unparked cores and comparing different core configurations. Both the 2+2 and 4+0 core configurations show even loading scenarios and also show a performance improvement when unparking the cores. Meanwhile the opposite is true when unparking cores with a 4+4 configuration. Thread loading and assignment becomes sporadic, causing a drastic decrease in performance. The previous statement alone doesn't show it's an issue with Firestrike alone. What really seals the deal however, is when testing a benchmark optimized for highly threaded situations.
For this purpose I chose Cinebench, testing with all cores parked and unparked. After three runs for each core park setting, the scores, loading, and thread assignment was almost Identical. These observations fall in line with the statement AMD recently made about optimization for Ryzen being a per program effort, and not a Windows 10 scheduling issue.
Before I wrap up this portion of my mini review, I would again like to bring to your attention to the issue of random score drops on default W10/bios settings. After 12+ hours of testing, I have not found any leads, but my best hypothesis remains the issue is likely due to no optimization of the Ryzen architecture for Firestrike.
TLDR
- The CCX complex doesn't cause any notable performance loss (~1% worst case)
- Unparking cores through the W10 power plan shows a ~5% performance gain with 8 total Threads (2+2 or 4+0)
- Unparking cores through the W10 power plan with all 16 threads active can cause up to a 31% performance loss
- Firestrike doesn't appear to be well optimized for Ryzen; at least with all 16 threads active
Part Two
For the second part of this mini review I took some time benchmarking the performance differences between W10 power plan options, different core park settings with power plans, and how ram/infinity fabric frequency all affected the Firestrike combined score. Additional testing of physics score scaling with ram frequency was also tested.
Test Setup:
- R7 1700 @ Stock
- Gigabyte AX370 Gaming 5 (F5d Bios)
- 2x8GB G.Skill DDR 3200 @ multiple frequencies and timings
- EVGA GTX 1070 FTW2 @ Stock (376.98 WHQL)
- EVGA 750w Supernova G2
- Windows 10 Home 64-bit (Build 1607)


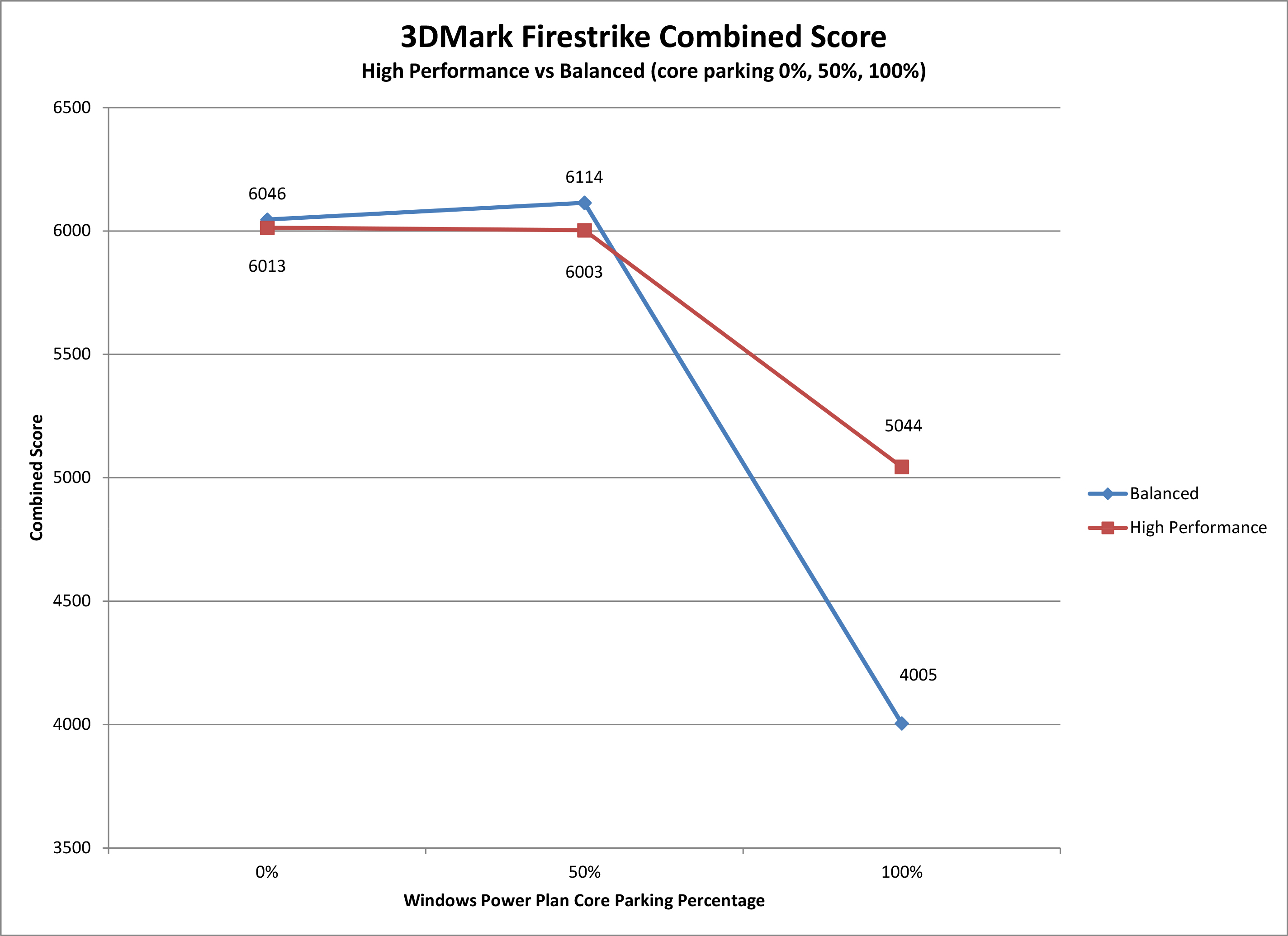

Increasing Firestrike Combined and Physics Scores: What worked
- Overclocking the CPU
- Overclocking the RAM/Infinity Fabric
- Unparking cores with 8 total threads (4+0 and 2+2)
Increasing Firestrike Combined and Physics Scores: What didn't work
- Switch between high and balanced modes @ the same core park settings
- enable Message System Interrupt for the Nvidia drivers
- unparking cores with 16 total threads (4+4)
- enabling maximum gpu performance in the Nvidia driver settings
** Feel free to make suggestions or corrections
*** Will edit in the future to showing some combined score scaling with CPU oc's
A few weeks back I spent a bunch of time benching my Ryzen setup. After many hours of benchmarking and documenting results, I found a handful of useful tweaks and general improvements that can be made however, there was one glaring issue that still doesn't make sense. The huge performance discrepancy when running specific core parking settings within the Windows 10 power plan settings in the Firestrike combined test.
image
I first noticed the issue when I was running batches of 3DMark runs to check ram frequency scaling. My scores would randomly drop by approximately 20% for no reason; I hadn't changed a single bios or windows setting for anything. I then ran a batch of tests to see how often this issue would occur, and found that approximately every 1.5 out of 5 runs my combined score would drop at the same settings (I ran a total of 20 tests at the same settings).
To keep this brief, this issue lead me down two paths. The first being the W10 power plan core parking setting and the second investigating whether or not core/CCX configuration had anything to do with the problem. For part one I exclusively used AMD's new Ryzen Power Plan, and simply adjusted the core parking values for testing purposes.
Test Setup:
- R7 1700 @ Stock
- Gigabyte AX370 Gaming 5 (F5G Bios)
- 2x8GB G.Skill DDR 3200 @ 3200 14-14-14-34 1T 1.35v
- EVGA GTX 1070 FTW2 @ Stock (381.65 WHQL)
- EVGA 750w Supernova G2
- Windows 10 Home 64-bit (Creators Update)
Part One
First we will look at how the Windows 10 core park settings affect the Firestrike Combined Score with the AMD Ryzen Power Plan. Below the Combined test was run three times with the stock R7 1700 at 0% (all cores parked) and at 100% (all cores unparked) via the W10 core parking option.
Here we can clearly observe one of the issues at hand. When W10 has all cores unparked (100% setting in power options), the Combined test performs signifcantly worse than with all cores parked. This behavior is only observed with both CCX enabled and 16 threads active, or the R7 1700 being at its' stock configuration and clock speeds. Performance drops on average by 22.5%, with an extreme delta of a 31% loss in performance. Is this due to threads being spread across the CCX? Let's find out.
Next I ran the same test but with the R7 1700 set to 2+2 and 4+0 two observe if latency due to threads being spread across the CCX was detrimental to performance. This was done using the downcore configuration options within the bios.
The results were VERY interesting to say the least. Not only had the behavior due to core parking been reversed, and performing like one would expect, there was almost no performance penalty due to cross CCX communication. With all the cores unparked the performance difference between the 2+2 and 4+0 configuration was 0.4%. The difference with all cores parked was 1%. Both of these values are what I consider to be within margin of error; CCX communication seems to incur no performance penalty.
It was starting to seem like the issue was directly related to how Firestrike itself was dealing with assigning threads and loads properly. This hypothesis seems to ring true when we take a look at performance across threads for each configuration. Thread assignment and loading was observed using the W10 task manager performance monitor.
Below we look at the difference in thread assignment and activity between all cores parked and unparked with the stock 1700.
With all cores parked, thread assignment is sequential from CPU0 to CPU15 with activity falling at CPU9 onward.
With all cores unparked, thread assignment is sporadic with the load spread unevenly across the 16 threads. Having all cores unparked also resulted in a consistently worse combined score, and with this uneven load/thread assignment it makes perfect sense.
Moving on to the 2+2 and 4+0, thread assignment and loading seems to be identical for each configuration. The major difference here being that again we see with all cores parked, thread assignment/load is sequential. When the cores were unparked, thread assignment was more sporadic, but loading was consistent between the 2+2 and 4+0 configuration. This is slightly different from the extremly sporadic loading and thread assignment we saw with the CPU configured for 4+4 with all cores unparked. Unfortunately there is no 8+0 Ryzen cpu to compare.
Now what does all of this mean? The most accurate conclusion I can make from this is that there are clearly some threading issues with the Firestrike combined test. Why Firestrike and not Windows you say? The proof is in the difference in thread loading with unparked cores and comparing different core configurations. Both the 2+2 and 4+0 core configurations show even loading scenarios and also show a performance improvement when unparking the cores. Meanwhile the opposite is true when unparking cores with a 4+4 configuration. Thread loading and assignment becomes sporadic, causing a drastic decrease in performance. The previous statement alone doesn't show it's an issue with Firestrike alone. What really seals the deal however, is when testing a benchmark optimized for highly threaded situations.
For this purpose I chose Cinebench, testing with all cores parked and unparked. After three runs for each core park setting, the scores, loading, and thread assignment was almost Identical. These observations fall in line with the statement AMD recently made about optimization for Ryzen being a per program effort, and not a Windows 10 scheduling issue.
Before I wrap up this portion of my mini review, I would again like to bring to your attention to the issue of random score drops on default W10/bios settings. After 12+ hours of testing, I have not found any leads, but my best hypothesis remains the issue is likely due to no optimization of the Ryzen architecture for Firestrike.
TLDR
- The CCX complex doesn't cause any notable performance loss (~1% worst case)
- Unparking cores through the W10 power plan shows a ~5% performance gain with 8 total Threads (2+2 or 4+0)
- Unparking cores through the W10 power plan with all 16 threads active can cause up to a 31% performance loss
- Firestrike doesn't appear to be well optimized for Ryzen; at least with all 16 threads active
Part Two
For the second part of this mini review I took some time benchmarking the performance differences between W10 power plan options, different core park settings with power plans, and how ram/infinity fabric frequency all affected the Firestrike combined score. Additional testing of physics score scaling with ram frequency was also tested.
Test Setup:
- R7 1700 @ Stock
- Gigabyte AX370 Gaming 5 (F5d Bios)
- 2x8GB G.Skill DDR 3200 @ multiple frequencies and timings
- EVGA GTX 1070 FTW2 @ Stock (376.98 WHQL)
- EVGA 750w Supernova G2
- Windows 10 Home 64-bit (Build 1607)
Increasing Firestrike Combined and Physics Scores: What worked
- Overclocking the CPU
- Overclocking the RAM/Infinity Fabric
- Unparking cores with 8 total threads (4+0 and 2+2)
Increasing Firestrike Combined and Physics Scores: What didn't work
- Switch between high and balanced modes @ the same core park settings
- enable Message System Interrupt for the Nvidia drivers
- unparking cores with 16 total threads (4+4)
- enabling maximum gpu performance in the Nvidia driver settings
** Feel free to make suggestions or corrections
*** Will edit in the future to showing some combined score scaling with CPU oc's



")



